
Getting your head around any new technology stack requires a lot of research and with that, you’re introduced to all the acronyms, terminology and how all its pieces fit together. The exact same happened to me when I started learning Kubernetes. One of the first questions I had, was “what’s the difference between a DaemonSet and a ReplicaSet?". A ReplicaSet is probably one of the first concepts that you’ll learn, cause it’s such an important part of what you can achieve with Kubernetes, but shouldn’t be confused with a DaemonSet; also a critical feature.
So with that said, let’s dig in… Let’s compare these two functions in a little more depth.
DaemonSet
kubernetes.io docs - daemonset
The official documentation explains DaemonSets as:
A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
In other words, a DaemonSet will ensure that all eligible nodes run a copy of a specific pod. “But, how do we enable a node to run a copy of our pod?”, you may ask. In your DaemonSet’s definition file (yaml), we can specify a key-value pair for the DaemonSet controller to match to the label assigned to a node. This key-value pair is defined in the .spec.template.spec.nodeSelector parameter in your DaemonSet definition file, this is the one we’ll be using in our example below. But we can also use the .spec.template.spec.affinity parameter and the DaemonSet controller will create pods on nodes that match our node affinity. And if we don’t specify either of these parameters the controller will create our pod on all the nodes in our cluster. But I think the biggest benefit here is that if we add new nodes to our cluster, and if labels are used and they match the nodeSelector parameter, then our pods will automatically be created on the new nodes.
When to use DaemonSets?
Is it important that a copy of your pod is always running on specific nodes? And is it important that our daemon pods start before any of our other pods? Then use a DaemonSet. A few examples of DaemonSets:
- a monitoring daemon.
- a log collector daemon.
Pictures always help
For our example, we have a key of ‘type’ and values of ‘prod’ and ‘UAT’ assigned to our nodes. These are assigned to the nodes with the kubectl label node [node_name] [key]=[value] command.
i.e. kubectl label node worker-node-01 type=prod
Below, we can see that our pod has been created on our nodes labelled with type=prod, and the node with type=UAT label has been excluded.
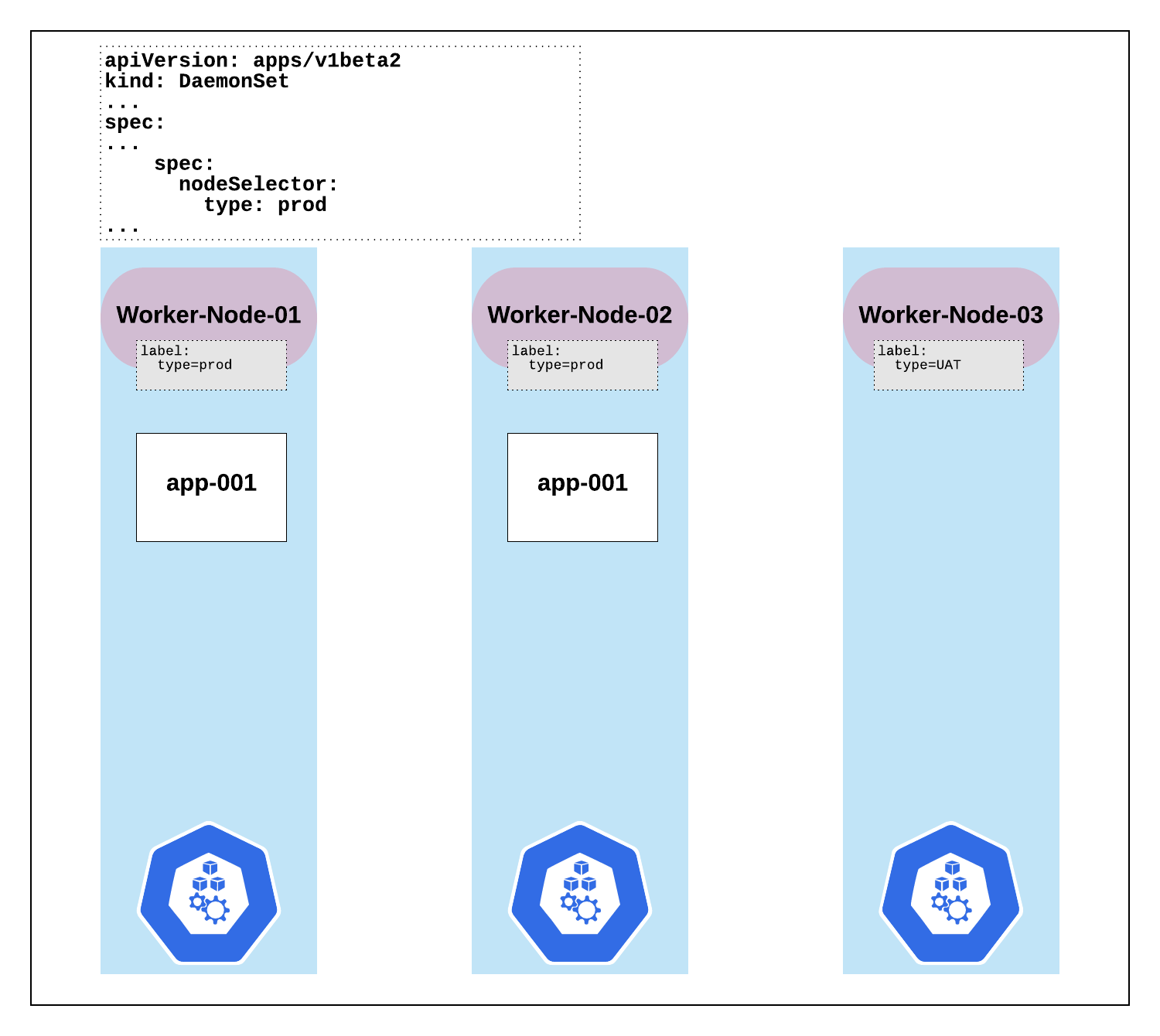
An example of a DaemonSet definition file:
apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: app-001
spec:
selector:
matchLabels:
app: app-001
template:
metadata:
labels:
app: app-001
spec:
nodeSelector:
type: prod
containers:
- name: main
image: hubUserName/app-001
ReplicaSet
kubernetes.io docs - replicaset
The official documentation explains ReplicaSets as:
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.
Basically what this means is that you can describe the number of pods required for your application, and ReplicaSets will ensure that this state is maintained. If we lose our worker-node-03, we have two pods that need a new home, the Replication Controller will deploy those two pods on other, functioning worker nodes, permitting they have enough spare resources.
We can’t dive too deep into ReplicaSets without discussing Deployments, and this is because our Deployment is what creates and manages our ReplicaSets, which in turn creates our pods. You’ll hardly ever need to manage ReplicaSets directly, but rather manage them via the application’s deployment configuration.
Thus, our Deployments and ReplicaSets work hand-in-hand, and my favourite benefit of Deployments and ReplicaSets is their ability to handle rolling updates. Let’s say we have a version2 of our application ready to be deployed, with rolling updates we can update our deployment with the new image to use (version2), and a brand-new ReplicaSet is created referencing the new image. The deployment assists in the migration all the way. While pods are migrated from the old ReplicaSet (v1) to the new ReplicaSet (v2), if we run into an issue the new ReplicaSet (v2) will never enter the READY state, and the original ReplicaSet is still working, so we never run into a broken deployment situation, our v1 pods are still up and serving requests. So technically pods aren’t moved or migrated, from one ReplicaSet to another; in fact, new pods, with the new version (v2) are created in a new ReplicaSet and once the new ReplicaSet (and its pods) are successfully deployed, the old ReplicaSet and its pods are killed.
When to use ReplicaSets/Deployments?
If you have an application and require it to have a set number of pods running, we’ll use a ReplicaSet via the Deployment configuration.
Let’s draw it out
In the diagram below, 8 replica pods deployed to our 3 worker nodes. A snippet of the yaml file is included. A full example of the file is to follow below. As we can see we requested 8 pod replicas to be deployed on our nodes. As mentioned ReplicaSets guarantee that, in this case, these 8 pods will always be running, at any given time, even if we lose a node.
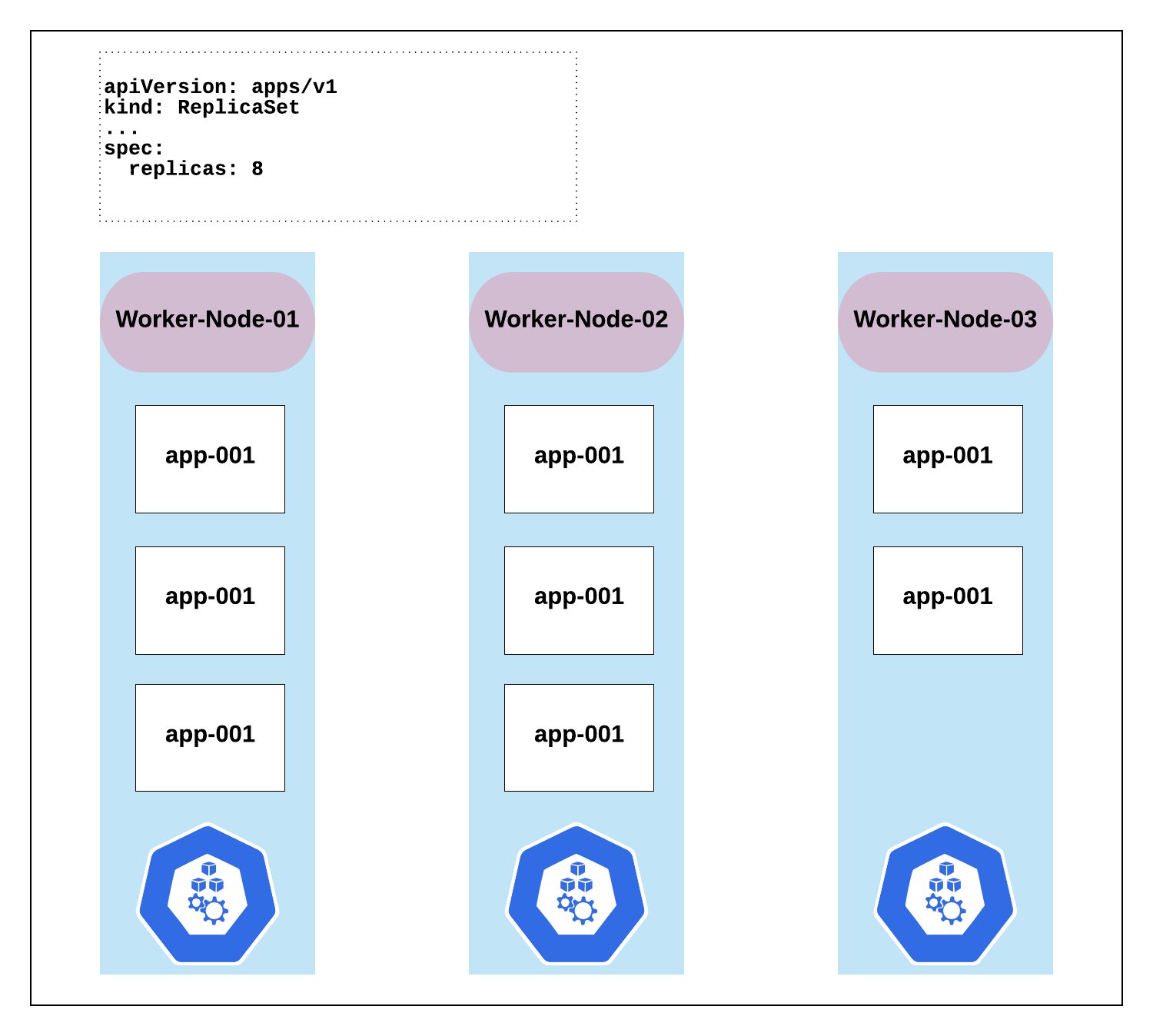
An example of a ReplicaSet configuration:
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
annotations:
name: app-001
labels:
app: app-001
spec:
replicas: 8
selector:
matchLabels:
app: app-001
template:
metadata:
labels:
app: app-001
spec:
containers:
- image: hubUserName/app-001:v2
name: app
Quick Summary
We’ll use a Deployment/ReplicaSet for services, mostly stateless, where we don’t care where the node is running, but we care more about the number of copies of our pod is running, and we can scale those copies/replicas up or down. Rolling updates would also be a benefit here.
We’ll use a DaemonSet when a copy of our pod must be running on the specific nodes that we require. Our daemon pod also needs to start before any of our other pods.