
The need for a private cluster will be different for every company, but the most common requirement stems from a security point of view. As developers, architects and Ops teams become more comfortable with Kubernetes and its complexities, we’ll see more and more applications (that fit containerized environments) be pushed to Kubernetes clusters. It’s this rise in popularity that also brings malicious activity to the ecosystem. To add another layer of security to our platform we can ensure our cluster is private.
Opting for a private cluster sparks a whole array of questions, and the answer to each question changes our cluster architecture ever so slightly, and it can easily add layers of complexity. Does it simply mean that our worker nodes won’t get a public IP address assigned? Can the worker nodes still access the internet, just via a NAT-Gateway? Where does our Kube-API run, and how do we and our worker nodes access it? What does “private cluster” mean for ingress, and what about container images?
In this post we’ll discuss a private cluster with EC2 worker nodes in private subnets, and what that all means and issues that could cause some headaches down the line and how to prevent them.
Communication between master and workers
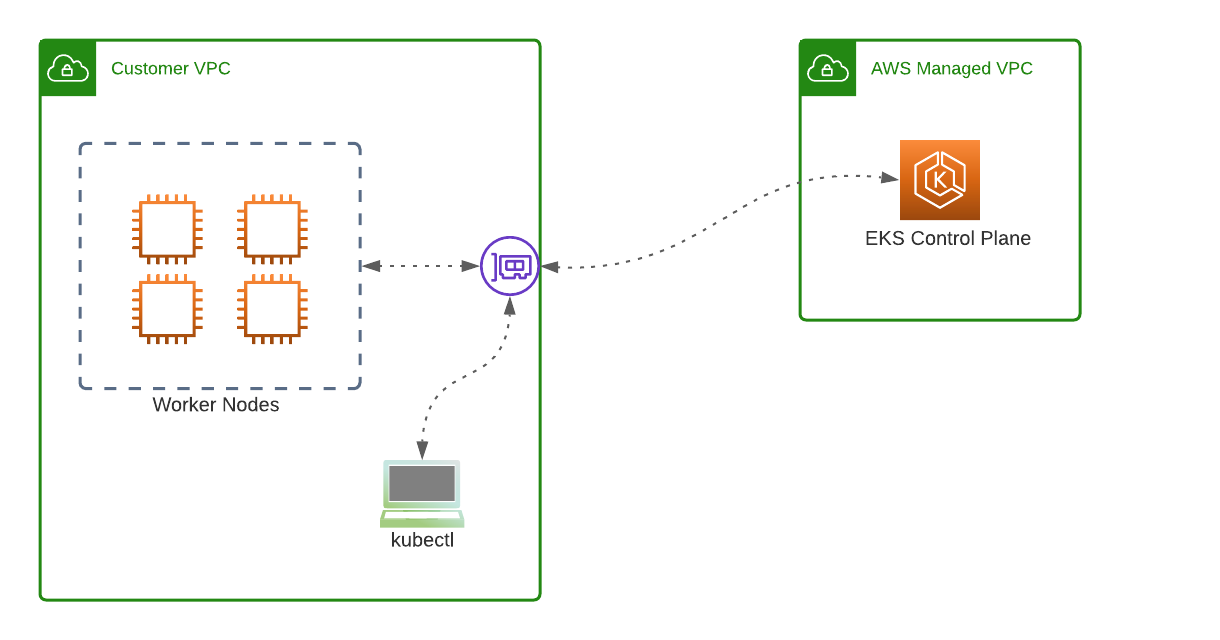
A key part, which helps with the understanding of private clusters, is firstly understanding the EKS service architecture with regards to master vs worker nodes. And secondly, keep in mind that EKS is a managed service, which means there’s some sort of separation needed between AWS, and customer-managed. EKS, being a managed service means that AWS manages our master nodes/control plane for us (we can opt for managed worker nodes too). We don’t have access to our master nodes. We can’t even see them in our EC2 console. This is because they don’t run in our VPC, they’re running in an AWS owned VPC which is linked to the one we have access to. The EC2 instances that run in our VPC, are the worker nodes (data plane). It’s these nodes that will host our pods.
There’s of course some communication needed between master and worker nodes, and between worker nodes and the container registry. With a standard cluster (with internet access) this communication is easy, and is possible “out of the box”. With our private cluster, we need to make provisioning for this communication. This is done via VPC-Endpoints. More on this later.
Fun fact; with our Kube-API set to private (running inside our VPC), the worker nodes connect to a shared ENI to get to the master nodes in the AWS managed VPC.
Tagging Requirements
We’ll get to eksctl shortly, which takes care of these tagging requirements (at the time of writing). But if you opt for a manual way (i.e. the AWS console) of creating the cluster, check these tagging requirements on all related objects.
Creating the cluster
When it comes to creating the private cluster, I would recommend using eksctl. It takes care of a lot of the prerequisites with regards to subnet tagging and IAM roles with the correct policies attached. With a cluster file like the one below, we can specify all the required parameters beforehand, and also add this file to version-control so we can easily recreate this cluster when needed.
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: quix-cluster
region: eu-west-1
vpc:
id: vpc-11eeef444cc1effee
subnets:
private:
eu-west-1a:
id: subnet-00fffe555aa4ece1a
eu-west-1b:
id: subnet-00fffe555aa4ece1b
clusterEndpoints:
privateAccess: true
managedNodeGroups:
- name: managed-NG
instanceType: t3a.medium
desiredCapacity: 2
privateNetworking: true
ssh:
publicKeyName: eu-west-quix-key
A few things to point out here; notice the privateAccess=true in the clusterEndpoints section; this part means that our Kube-API server will be provisioned inside our VPC, and will only be reachable from within the VPC. This is critical from a security point of view. We don’t want to go through all this effort of creating a private cluster and then expose our API.
But before we just run an eksctl create cluster, there’s some work to be done. As you can see we pass the VPC and subnet IDs. If we’d like to utilize existing infrastructure, we’ll need to create them first. However, by omitting these parameters eksctl will create them for us. But I prefer to run my EKS cluster in my existing VPC and subnets, but that’s just for my use case. Do keep in mind, if you’re going to create a private cluster, you must provide eksctl with private subnets. How do you know if your subnet is public, or private? If a subnet is associated with a routing table, with a route to an internet gateway, it’s a public subnet.
Keep in mind that our subnets are private, and our API server is also inside our VPC, but we need the components on our side (our VPC) to communicate with a few key AWS hosted services to function properly. For this to work, we’ll need to create VPC endpoints. "
A VPC endpoint enables connections between a virtual private cloud (VPC) and its supported services, without requiring that you use an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection. Therefore, your VPC is not exposed to the public internet."
- com.amazonaws.[AWSRegion].ec2
- com.amazonaws.[AWSRegion].ecr.api
- com.amazonaws.[AWSRegion].ecr.dkr
- com.amazonaws.[AWSRegion].s3 – For pulling container images
- com.amazonaws.[AWSRegion].logs – For CloudWatch Logs
- com.amazonaws.[AWSRegion].sts – If using Cluster Autoscaler or IAM roles for service accounts
- com.amazonaws.[AWSRegion].elasticloadbalancing – If using Application Load Balancers
- com.amazonaws.[AWSRegion].autoscaling – If using Cluster Autoscaler
- com.amazonaws.[AWSRegion].appmesh-envoy-management – If using App Mesh
- com.amazonaws.[AWSRegion].xray – If using AWS X-Ray
These are quite pricey, it could be a good idea to only provision the ones you need.
Container Images
The larger admin headache with private clusters comes in with the images for our applications that run on the cluster, as well as any kind of add-on that we need to install for our cluster. By add-on I mean, cluster-autoscaler, cert-manager, and metrics server, just to name a few. For a bare-bones cluster, EKS pulls the container images it needs from a shared, regional, AWS owned container registry, hence the need for the VPC endpoints. When it comes to expanding on our cluster, we will need to provide a copy of the container image in our ECR. Maintaining and keeping this image up to date, will also fall on us.
But why can’t we get our add-on images from the same registry? Well, AWS only hosts the images needed to run a basic cluster. If you want additional features, you’ll need to get these images from the ‘vendor’/owner of that add-on, and because our cluster is doesn’t have internet access, it can’t reach the likes of Dockerhub.
To use the cluster-autoscaler as an example, when we are following the cluster-autoscaler documentation, in step 1 of the section “Deploy the Autoscaler” we need to deploy a specific yaml file, which runs the autoscaler application in our cluster. Deploying this to our private cluster, we first need to upload this image to our container registry (ECR) and update the container image parameter in the YAML file to point to the same. Remember the autoscaling VPC endpoint.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cluster-autoscaler
namespace: kube-system
labels:
app: cluster-autoscaler
spec:
replicas: 1
selector:
matchLabels:
app: cluster-autoscaler
template:
metadata:
labels:
app: cluster-autoscaler
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8085'
spec:
priorityClassName: system-cluster-critical
securityContext:
runAsNonRoot: true
runAsUser: 65534
fsGroup: 65534
serviceAccountName: cluster-autoscaler
containers:
- image: k8s.gcr.io/autoscaling/cluster-autoscaler:v1.21.0 <<---
name: cluster-autoscaler
resources:
limits:
cpu: 100m
memory: 600Mi
requests:
cpu: 100m
memory: 600Mi
[...]
Additional Considerations
An important consideration for our entire setup is to understand how we’re going to reach our Kube-API running within our VPC. This will be different for every environment, and how your on-prem environment is connected to your cloud environment plays a big role here. We have a few options; ideally, the on-prem (office/DC) network and the private VPC should be connected either via a VPN connection, or a Transit Gateway. And if our laptop is connected to the same network and routing is correctly configured, we can then run the kubectl commands locally on our laptops and hit the Kube-API server inside the VPC. From a routing perspective, and if we refer back to the diagram from earlier, we just need to reach the shared ENI in our VPC, this again is connected to the AWS managed VPC where our Kube-API runs.
A second option is to run kubectl on a bastion-host inside our VPC. This entails spinning up a bastion EC2 instance, either in an adjacent public subnet or in our existing private subnets. If we opt for a bastion EC2 in a public VPC, we will need to peer our VPCs and ensure our Security Groups are configured to allow 6443 from the public VPC to the private VPC.
Ingress
For apps running in our private cluster with a user interface that needs to be accessed by our users, we will of course need to configure ingress resources. The cloud Kubernetes offerings are really powerful here, and the integration between their services is what will make a customer opt for one over the other. By default when configuring an ingress resource, with a few special annotations, will trigger some nifty events on AWS’s side, and spin up a load balancer for you, so traffic can be routed to your services running inside your cluster.
We can specify specific load balancing features, and ensure the load balancer is running in the correct subnets and listening on the right ports, with an SSL cert just by adding some annotations to the object. In the code below we do just that; we ask AWS to give us an internal (scheme) ALB (ingress.class), in our private subnets (subnets) and ensure it uses the cert we uploaded to AWS certificate manager (certificate-arn). We also specify a group name; this is a relatively new feature that allows you to reuse your ALBs. So when we create another ingress resource, and we give it the same group name, AWS will merely configure the existing ALB with new listeners and rules, instead of giving your a brand new ALB. This 1:1 ratio of ALB to Service can start costing you a pretty penny.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: default
name: ingress-h2c-app
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:eu-west-1:xxxxxxxxxxxx:certificate/11111111-2222-3333-4444-5555555555555
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/scheme: internal
alb.ingress.kubernetes.io/group.name: h2c-groupname
alb.ingress.kubernetes.io/target-type: instance
alb.ingress.kubernetes.io/subnets: subnet-00fffe555aa4ece1b, subnet-00fffe555aa4ece1a
spec:
rules:
- http:
paths:
- path: /hello-world
pathType: Prefix
backend:
service:
name: hello-world
port:
number: 8080
Troubleshooting the cluster
A few issues I have faced while building private clusters mainly came down to configuration issues. Cloud environments can become very intricate with lots of moving parts and integration points, it’s important to understand where to look for the errors and understand in which direction they’re trying to point you in. There could be multiple root causes for each of these issues, and of course not the only issues you could face with your cluster, but these are the main ones that have cost me the most time.
Nodes not joining the cluster
If you’re using an eksctl config file similar to the one in this post, one that includes a nodeGroup, eksctl will kickoff two separate CloudFormation templates, one for the cluster and a second one for the nodeGroup. CloudFormation is a good starting point for troubleshooting this issue. Some key points/symptoms.
- Your cluster is up and running
- EC2 instances get provisioned
- EC2s get tagged correctly and with the correct Security Groups
But they never join the cluster. Meaning, when you navigate to your EKS console, they’re never in the nodes list. You’ll see the same with a kubectl get nodes command. One thing to note when using eksctl and providing your own VPC and subnets; eksctl doesn’t take care of any missing NACL rules. This can cause some issues with communication between workers and control nodes. This has cost me more time than I’m willing to admit, a simple NACL rule to allow communication in and out of your subnet will save a lot of headaches.
The reason for this is that the new worker node cannot contact the API to download configs.
Nodes not entering ready state
So your worker nodes get provisioned AND they join the cluster, but Kubelet never reports a ready state. Your CloudFormation template will fail, just like in the previous error, and again this is a good starting point for your troubleshooting. A few items to check:
- EC2 tags
- Security Groups and NACLs
- EC2 logs (specifically Kubelet)
The root cause for me has always been VPC endpoints and their access policies. If the worker node cannot connect to VPC endpoints, it can’t download some container images.
Unable to pull images
Again, this is mainly due to us having a private cluster, and connectivity to services and their endpoints are via alternative routes. Ensure your environment meets the requirements for VPC endpoints
Conclusion
There’s a lot to consider when opting for a private cluster, and not a requirement for every company or team. You can get a production-grade cluster while running it in public subnets, with some additional security measures. But there are instances where security policy will require private clusters.
The bottom line is that with your control-plane traffic not traversing the public internet, your API not accessible from the outside, and your worker nodes not available from the internet either, private clusters surely are more secure, and thus your attack surface is greatly reduced.
This configuration could very well become the norm if the Kubernetes uptake continues on this upward trend as we’ve seen in the last couple of years. There have been several instances some cryptojacking incidents where container runtimes are compromised, or the Kubernetes Dashboard is incorrectly configured to be public, with no authorization.
Private clusters do come with a set of hurdles to overcome, but not impossible. If at the end of the day you have a more secure platform, would it not be worth it to ensure your workloads, customer information, and critical data are safe?